本文讲述在使用mongo进行分布式存储的时候,对于片键和索引的设计思考,要点 :
1. 分布式存储的两大需求
2. 分片片键和查询索引设计的一般原则
3. 分成多少片合适
4. 举例分析如何设计片键和索引
5. 举例说明不能随便套用索引
6. mongodb自身的分片的局限性
一. 分布式存储的两大需求
1-1. 查询局部化
根据查询条件,能够定位到某一台机子或者几台机子上去做查询,即最好不要查询所有的机子
1-2. 数据均衡性
每一台机子的数据量要差不多,即不能让数据过分集中于某几台机子,那样会导致那几台机子太累而成为性能的瓶颈,而其他机子太空闲
二. 分片片键和查询索引的一般原则
片键最好是索引的前缀
比如,我的分片片键是{ a },我的查询索引是{ a, b }。它隐含的要求是 :
一是首先这个{ a }片键要能够在插入新的数据时,比较均衡地把数据分散到不同的机子上
二是我们大多数的查询是使用{ a, b }作为查询条件的,这样才能快速地把查询定位到少数的几台机子上
原则上是这样,最大的难题是:
1. 往往我们很难找到这样的片键和索引,即很多时候,我们找不到这样的a和b,或者说我们的有效数据中找不到这样的字段。
需要我们利用有效数据字段,来人为构造出这样的a和b。
2. 片键和索引往往无法满足上述说的分布式存储的两大需求,甚至很多时候这两个需求是有矛盾的。
矛盾情况1 :
比如我们可以用简单的Btree索引来作为片键,由于Btree索引是比较聚集的,能够使得我们的查询是局部化的。
但是Btree索引往往导致数据在各个机子上很不均衡,这也是由于这种索引比较聚集的原因。
设想一下,你有三个分片结点,你的片键是一个整数字段,像一般的自动分片,会把[0,100]的分到第一个分片,
把[101,1000]的分到第二个结点,剩下的分到第三个结点,
你也发现了吧,无论怎样分,都无法保证三个区间的长度相等,所以结果是违反了数据均衡性的需求。
矛盾情况2 :
比如我们可以用简单的hash索引来作为片键,毫无疑问,只要你的字段基数足够大(基数大的意思即取值范围比较大),
数据的均衡性是可以靠哈希的分散性来保证的。但是,当你做查询的时候,如果你的查询条件不是这个字段呢,
就只能查询所有的分片结点再汇合了,违反了查询局部化的需求。
因为我们的查询条件很可能是多字段的,而目前的哈希索引还只能支持单键,
所以你脑袋中设想的类似{ key1 : hashed, key2 : 1, key3 : 1 }的多级索引或多级片键是无法实现的,
如果实现了这种复合哈希索引,那问题就彻底解决了,可是目前还未实现...所以单纯地使用哈希来进行分片,很多时候是无法解决问题的。
三. 分片数量取多少合适
num1 ≈ 存储总量 / 单机可挂载容量
num2 ≈ 工作集大小 / 单机内存
num3 ≈ 并发总量 / ( 单机可承受的并发量 * 0.8 )
// 此处的0.8是个一般值,在分片环境下,由于有了集群调度,每台机子的能力会比单机时降低一些
最终的分片数量 = max( num1, num2, num3 )
工作集 = 索引 + 常用热数据
mongodb是采用内存映射的方式来管理内存和磁盘的(目前mongo已经有了自己的存储引擎,比如WiredTiger就不再是内存映射方式的)。
为了让缺页中断的次数降低,就要求内存应该大于工作集的大小。
但是在单机环境下是很难保证的,因为有时候索引的大小甚至比实际数据还要大。
所以此时只能依赖分片了,那分成多少片合适呢?每片的内存需要多大呢?这就要求我们必须知道索引和热数据的大小。
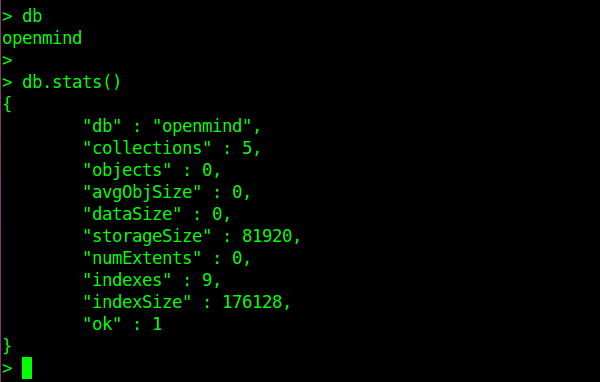
如上图,切换到你的库,然后通过db.stats()来查看,其中的indexSize便是这个库下的所有索引的字节数
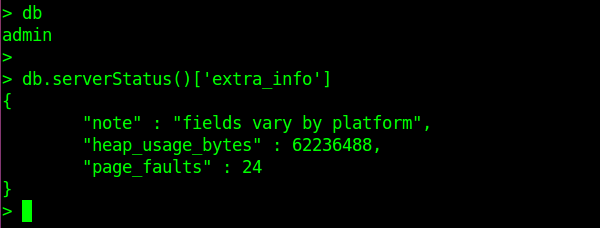
如上图,进入admin库,然后通过db.serverStatus()来查看,它会打印出最近15分钟内的情况。
此处我只打印出extra_info这个字段(当然很建议也去看看其他字段的信息) :
其中的heap_usage_bytes便是内存中的热数据占的字节数,
其中的page_faults是最近15分钟里面发生的缺页中断的次数。
四. 举例说明如何设计片键和索引
例如我们的数据是用户发表的动态。
考虑到每个用户会发表很多动态,可能每天就有好几条,所以合理的查询是按时间降序分页查询,或者是按时间段进行查询,总之不会一次性就返回所有的记录。
我们拿按时间段查询为例,来讲述几种方案的优劣:
4-1. 分片片键 = { user : 1, year : 1, month : 1 }
查询索引 = { user : 1, year : 1, month : 1, day : 1 }
让片键成为索引的前缀,感觉上去既达到了分片效果,
又能使用这个四级索引很快地定位到某几台机子上,快速查出某年某月某日的所有动态,或者查出某年某月的所有动态。
然而实际情况是,片键的第一个字段的基数太大,这种大基础的升序索引,它的均衡性是很差的。
当然像mongo提供了手动分片,你可以根据user的前几位字符来手动制定路由规则,但是一般的自动分片不推荐使用大基数的字段作为片键的第一个字段。
4-2. 分片片键 = { month : 1, user : 1 }
查询索引 = { month : 1, user : 1, year : 1, day : 1 }
使用month作为片键的主字段,好处是month是一个周期性的数据,且基数不是太大。
记住千万不要用递增的字段来作为片键的主字段 :
设想一下,你有10台分片机子,你用时间戳来作为片键的主字段,那么随着时间的推移,有些机子将再也不会有新的数据,这是及其不好的。
而使用month就恰恰避免了这种情况,而且片键的副字段user是一个基数很大的字段,它可以用来对分片内部的数据块进行分割。
然而,month这个字段的基数太小,如果我们的集群规模变大,超过12,那么多余的机子的利用率会非常低下。
4-3. 分片片键 = { shard : 1, user : 1 }
查询索引 = { shard : 1, user : 1, year : 1, month : 1, day : 1 }
其中shard是一个人为构造的字段,shard = func( year, month )
具体的算法是,比如日期是20160607,那么shard = (2+1)×(0+1)×(1+1)×(6+1)×06 = 252
这个片键的好处是 : shard的基数既不太大也不太小,而且shard这个值随着月份年份的增加,并不是一直递增的。
这是一个比较简陋的算法,如果你有更好的想法,告诉我哦。
五. 举例说明不能随便套用片键
例如我们的数据现在是用户维护的项目,它和上面论述的用户的动态内容一样,本质上都是”某人发布了啥“的记录。
乍一看,可以套用上面4-3中的方法,即 :
分片片键 = { shard : 1, user : 1 }
查询索引 = { shard : 1, user : 1, year : 1, month : 1, day : 1 }
似乎没什么问题。但是忽略了一点,它们的数据量的差别是非常大的 :
A. 对于用户发布的动态,一天就好几条,一下子返回所有记录是不合适的,按照时间段来查询是合适的。
B. 然而对于用户维护的项目,一个用户几年下来,维护的项目基本上也不会超过10个,还要必要分时间段查询吗?没有必要,而且是不能这么做。
设想一下,你在客户端上点了半天,也没点出来一个项目,好不容易点到一个月份有项目,这用户体验也太差了吧。
所以,这种情况下,一次性返回所有的项目,反而是个合适的做法。
既然查询方式发生了变化,那么我们的查询索引就要变,分片片键也就跟着要变,保持片键是索引的前缀。我的做法是这样的:
对项目表 :
分片片键 = { _id : 1 }
查询索引 = { _id : 1 }
对用户表 :
设置一个projects字段,它的值like [ id1, id2 ]
在每次往项目表插入一条数据的时候,记下这条新数据的自动生成的文档id,插入到对应的用户的projects字段中。
这样一来,项目数据能达到很好的均衡性,而且可以通过查用户表快速获得该用户所有的项目id,再通过id迅速路由到指定的分片结点上去查询。
六. mongodb自身分片的局限性
当你想使用一种比较个性化的分片策略时,mongodb自身的分片往往很难胜任。
拿快的打车这个APP来举例说明,该案例出自imooc上快的打车的技术分享,链接地址为 http://www.imooc.com/video/5181
核心的一个集合是司机的地理位置信息表,该集合中的每个文档都包含三个字段 :
司机基本信息
司机经度
司机纬度
看起来是是关系型的,因为mongodb的地理位置索引要优于mysql这类数据库,所以用mongodb来存。
这个集合的数据量也不大,总共一百万左右的司机,占用700M的空间,乍看之下真是没有必要做分布式,所以快的一开始采用的是复制集的架构。
其中主结点负责更新司机们的地理位置,若干从结点负责查找距离用户最近的司机们(读写分离)。
然而打车业务中,司机的地理位置信息的读写频率都是非常高的 :
读的频率大概是每秒1W次
更新的频率大概是每秒4W次
更新的频率远远高于读的频率,当然读的频率也是很高的了。
快的称它们的数据库服务器的配置是128G内存12核超线程,然后在如此庞大的更新操作下,让单纯的复制集的一台主结点去做更新,导致 :
从结点延迟就会被拉的很大
所以常常有司机表示接到订单后发现自己已经离用户好远好远了
下面讲讲快的解决这个问题的方案:
1. 首先,他们把整个中国,分成了很多的部分,可以理解成每个省作为一个部分,每个部分对应一个独立的复制集
比方说,江苏的司机,就让他们的数据仅停留在江苏那个复制集中。很容易理解,因为江苏的司机是不会开到其他省的去的。
2. 在更新司机们的地理位置的时候 :
根据司机是哪个省的,直接定位到对应的复制集上,让那个复制集上的主结点来完成地理位置的更新,这样做就能把写操作给分摊开来了。
3. 在用户查找最近的司机们的时候 :
A. 也会根据用户当前在哪个省,直接定位到对应的复制集上
B. 然后随机挑选那个复制集上的某个从结点来进行查询
// 这样做,等于是把查询做了二重的分摊,第一重是根据省份来分摊,第二重是利用若干从结点来分摊
你可能会疑问,不同省的交界处的查询会不会出问题 :
比如江苏和山东的交界处有一个用户,他稍微偏向于位于江苏地带,结果定位的时候分配到山东对应的那个复制集上去做查询了,会不会有这种问题。
我的理解是一般是不会的,第一通过提升定位的准度,第二是因为不同省份交界处一般是不会有司机的,哪个司机没事干开到边境上...
所以,快的打车,它这种自己实现了一个中间层来根据地域做分摊的方法,是比较好的。
它并不是mongodb传统的分片,因为mongodb传统的分片没法做到这种很个性化的分片,只能依赖自己实现中间层。
所以说,从灵活性和针对性上来看,中间层+复制集,这样的方式,是值得注意的。
七. 一些总结
7-1. 分片片键是查询索引的前缀
7-2. 除了哈希片键,非哈希片键建议使用多级片键
7-3. 多级片键中,片键的第一个字段最好不要是递增的
7-4. 多级片键中,片键的第一个字段的基数不要太大,也不要太小
7-5. 多级片键中,片键的第二个字段的基数大些比较好
7-6. 在找不到合适的字段做片键时,根据已有字段,构造新字段
7-7. 数据量的不同,查询方式便不同,片键与索引跟着也不同
7-8. mongo自身的分片很难用的时候,可以自己实现数据均衡的中间层